Listen to the audio version of this article (generated by AI).
AI just joined the payroll.
At Kalshi, the U.S.-regulated prediction-market platform where traders bet on real-world outcomes, an internal AI agent named Harrison is already performing work that looks a lot like analyst labor.
It tracks news, monitors competitors, recommends new markets, drafts contract language, and helps resolve markets when they close.
Functionally, AI is starting to look less like software you use and more like labor you deploy — planning, checking, calling tools, retrieving information, revising, and repeating the loop until the job is done.
And that kind of AI is far more compute-hungry than the chatbot world investors first fell in love with.
AI Agents Are Moving From Answers to Action
For the first few years of the generative AI era, the story was almost entirely about capability.
ChatGPT conducted and organized research. Sora stunned users with hyper-realistic video. Claude summarized documents, drafted emails, wrote code, and helped professionals move faster. It was dazzling.
At the same time, impressive as it was, this was still AI in its infancy.
The business model was straightforward: user asks, AI answers, company charges a subscription. The compute profile matched: modest inference on demand, a few thousand tokens in and out, and a model that mostly sat idle between queries.
But an AI agent is different. Give it an objective, and it goes to work — planning, executing, checking its own output, calling tools, querying databases, revising, and iterating until the task is complete. That continuous loop consumes inference compute on a vastly larger scale.
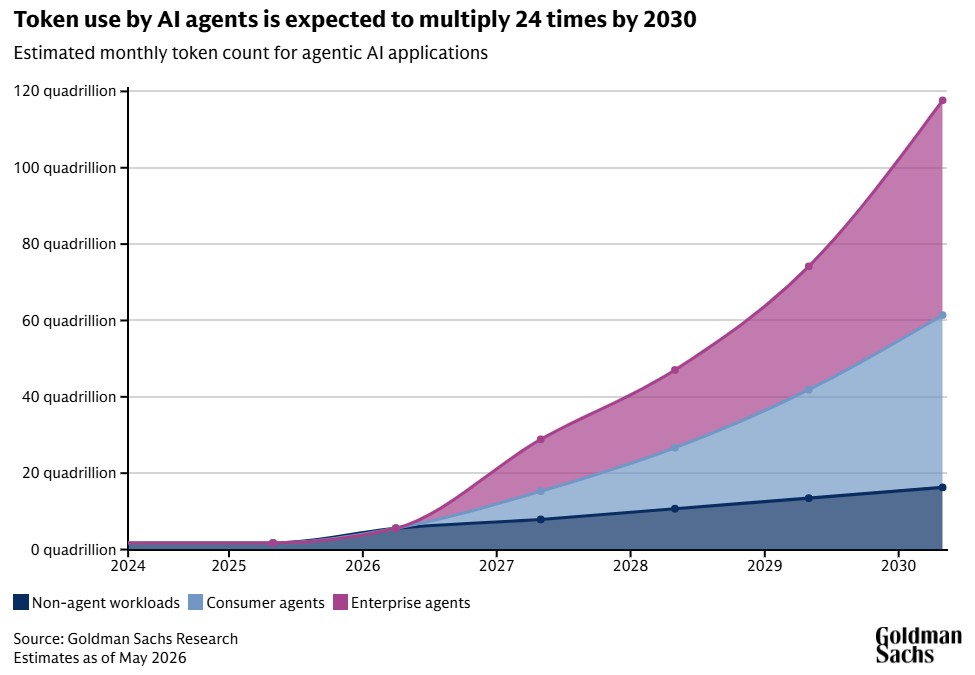
Gartner estimates that agentic workflows consume 5-30x more tokens per task than single-shot generative queries. Goldman Sachs sees the monthly token count for agentic AI applications reaching roughly 120 quadrillion by 2030.
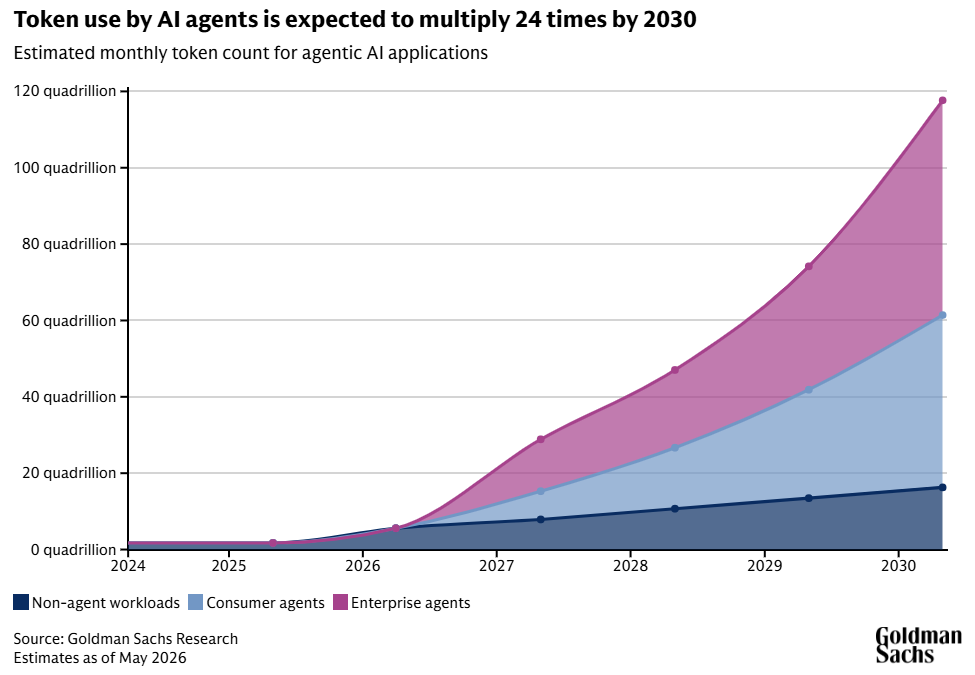
This is the structural shift that most investors are still underestimating.
Why Agentic AI Requires So Much Inference Compute
Harrison shows what agentic AI can do across information-heavy workflows:
- Ingesting and summarizing news, social media, filings, and market data
- Reasoning over that information to identify what matters for Kalshi’s open markets
- Drafting proposed contract language for new prediction markets
- Stress-testing that language for ambiguity, edge cases, or potential disputes
- Monitoring competitor platforms to benchmark Kalshi’s market offerings
Every one of those tasks is an inference call — often multiple — with tool use, retrieval, multi-step reasoning, and iterative revision layered on top. Agents like Harrison could be making dozens of API calls per task, around the clock.
Now multiply that by the number of enterprises building their own Harrison. Then multiply that by the number of workflows inside each enterprise that are ripe for agentic automation — compliance review, customer support, financial analysis, coding, procurement, legal research, sales outreach…
This is what we mean when we say we are at the very beginning of the inference demand supercycle.
The Investment Implication: Follow the Inference Demand
Follow the compute, and you’ll find the trade.
It doesn’t matter which app wins, which enterprise deploys the most agents, or which model — GPT, Claude, Gemini, Llama — powers them.
What matters is that every agent is sending traffic through the same physical infrastructure stack. And that stack is finite, expensive to build, and currently being stretched to its limits.
Each layer collects a different kind of toll.
Accelerators: Nvidia and AMD Power the Reasoning Loop
Nvidia (NVDA) and AMD (AMD) remain the engine room of inference compute. Every time Harrison runs a reasoning loop — planning, executing, checking its work — it draws on accelerated compute. Nvidia’s Blackwell GPUs remain the preferred hardware for many large-scale AI workloads, and the 12-month order backlog shows how intense demand remains. AMD, meanwhile, is gaining ground in cost-sensitive inference workloads as hyperscalers look for alternatives and bargaining power. Both benefit structurally from the agentic shift.
Networking and Custom Silicon: Lowering the Cost per Token
Every agentic workflow sends repeated traffic across the networking stack. Arista Networks (ANET) has continued raising its AI networking targets as demand from cloud customers accelerates. Its latest results showed revenue growth of 35% year over year, while management described the AI demand environment as unusually strong. Credo Technology (CRDO) supplies the active electrical cables that connect GPUs at the rack level. Broadcom (AVGO) and Marvell (MRVL) are designing the custom chips hyperscalers are deploying to run inference more efficiently and at lower cost per token.
Memory: The Bottleneck Behind Long-Context Agents
Agents maintain large context windows — tracking conversation history, tool outputs, retrieved documents, intermediate reasoning steps — making high-bandwidth memory (HBM) a critical resource. Micron’s (MU) latest quarter showed just how central memory has become to the AI buildout. Fiscal Q3 revenue surged to $41.46 billion, up roughly 346% year over year, while non-GAAP gross margin hit 84.9%. The company also guided fiscal Q4 revenue to $50 billion and said memory demand continues to exceed supply, with tight conditions expected to persist beyond calendar 2027. Only three companies on the planet manufacture HBM at commercial scale. Micron is the only U.S.-headquartered one.
Servers, Racks, and Power: The Always-On Agent Layer
All the GPUs running continuous agentic-scale workloads need to live somewhere and be kept cool. Dell (DELL) and Super Micro (SMCI) build the servers and racks. Vertiv (VRT) supplies the power and cooling infrastructure that keeps them running. In Q1 2026, VRT reported $2.65 billion in revenue — up 30.1% year over year — against a $15 billion order backlog. Training happens in big, intense bursts. Agentic inference is different: it can run continuously across millions of workflows. That persistent demand raises the importance of power and cooling infrastructure.
Storage: Fast Retrieval for Enterprise AI Agents
Agents need to retrieve information fast, requiring instant access to large datasets. That means high-performance storage is a must. Pure Storage (PSTG), Seagate (STX), and NetApp (NTAP) are likely beneficiaries as more enterprise workflows require AI systems with fast access to massive datasets. Pure Storage in particular has been gaining strength beneath the surface. In Q1 of FY2027, product revenue surged 55%, while subscription services accounted for 45% of total revenue. Operating profit jumped over 90% year-over-year to $159 million.
Optical Connectivity: The Overlooked Agentic AI Bottleneck
This may be the most overlooked constraint in the entire stack — and one of the next bottlenecks the market wakes up to. Moving data between GPUs, servers, and data centers at the speeds required for continuous agentic inference requires optical connectivity. As agent workloads move across servers, clusters, and data centers, more of that traffic depends on fiber, optics, and photonic interconnects. Coherent (COHR), Lumentum (LITE), and Corning (GLW) are building the infrastructure that makes high-throughput inference physically possible. The optics bottleneck is coming. These names are positioned for it before the crowd arrives.
The Bottom Line: Agentic AI Turns Compute Into Labor Cost
Kalshi’s Harrison is more than another headline. It’s a signal — that enterprise AI has crossed a threshold, from “interesting capability” to “operational necessity.”
When a company builds a purpose-built internal agent and deploys it into its core workflows, it is making a structural bet that AI will permanently change how the business operates.
That bet requires infrastructure… and lots of it.
We are at the very beginning of the inference supercycle — the period where AI demand shifts from episodic to persistent.
The companies supplying the accelerators, networking, memory, servers, storage, power, cooling, and connectivity behind that shift are not side bets on AI. They are the trade.
Because once AI joins the payroll, compute becomes the new labor cost.
The billionaires building sovereign AI from the inside already understand this. Their private capital has been moving into the physical layer of this buildout — energy, nuclear, fabrication, hard assets — for longer than the headlines suggest. Most of those positions aren’t available publicly.
Seven of them are.
Here’s what we know.
5 Stocks Our Experts Predict Could Double In the Next Year
By submitting your email, you'll also get a free pivot & flow membership. A free daily market overview. You can unsubscribe at any time.